Kris T. Huang, MD, PhD, CTO
Based on the notion of biological neurons, deep neural networks (DNNs) loosely mimic the networked structure of a (very) simplified brain of sorts. DNNs have revolutionized and automated a number of tasks that were once considered next to intractable, yet we appear to be reaching a plateau as we bump up against the limitations of DNNs. From the opaque nature of neural network models, susceptibility to adversarial attacks, to large data requirements, there are a number of weaknesses uncovered by research that have been quietly reminding us that although pure connectionist models like DNNs mimic biological systems, they remain for the time being rough approximations.

In “Chess and Checkers,” the third installment of our YouTube series exploring some of the quirks of deep learning, we demonstrate a third undesirable property of DNNs: catastrophic forgetting. At the heart of this is the question, “Can an old neural net learn new tricks?” In other words, can a neural network learn to do more than one task? Related to this is the ability to perform incremental training, or continual learning. These capabilities are considered critical stepping stones toward the goal of artificial general intelligence (AGI).

What is catastrophic forgetting? It’s the tendency for a neural network’s knowledge of previously learned task to be abruptly lost during training for a second task, to the point where performance in the first task nosedives. In our video sketch, I play the part of neural network that learned to play chess in the past, and then checkers later. At the start of the sketch, I’m playing checkers for a bit, but when we switch to chess, it seems I forgot where the pieces go, and who goes first. Perhaps even worse, I don’t even realize that this has happened. It’s a classic case of forgetting something to learn something new.

Humans forget, too, but there are several differences between catastrophic forgetting in DNNs and forgetting in humans. While behavioral studies in humans have shown that forgetting is part of learning, the result of this forgetting, perhaps likely its purpose, is to remove distraction. In catastrophic forgetting, on the other hand, it occurs to the extent that performance on any of the trained tasks becomes poor.
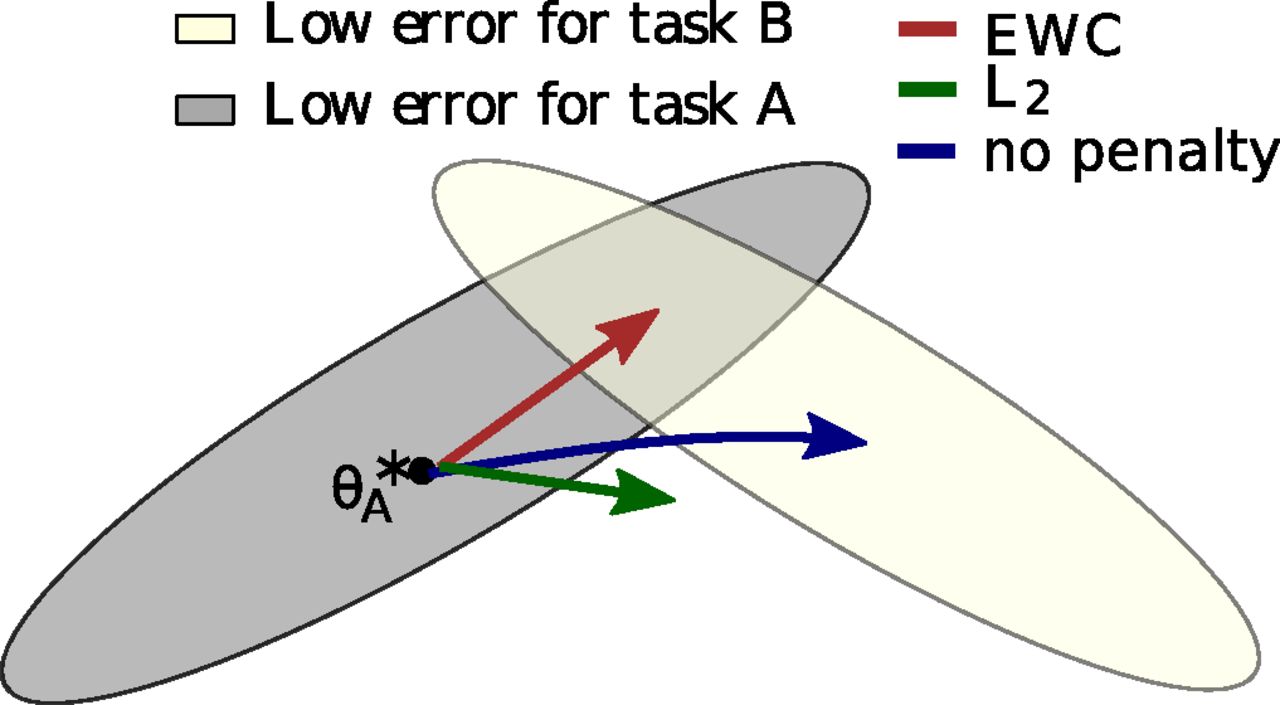
A conceptual look at elastic weight consolidation (EWC), a form of weight protection to mitigate catastrophic forgetting. The gray zone represents neural net parameters that produce good results for task A, and the beige zone represents good parameters for task B. Ostensibly there are parameters that produce good results in both tasks, and EWC preserves parameters important for task A while allowing training for task B to proceed. Other methods with lower or no weight protection, produce parameters that result in catastrophic forgetting of task A (no penalty) or possibly poor performance in all trained tasks (L2). Kirkpatrick, J. et al. Overcoming catastrophic forgetting in neural networks. https://www.pnas.org/content/114/13/3521 (2017).
The problem has been known as far back as 1959, but only in recent years have strategies to minimize catastrophic forgetting emerged. There are a number of methods, but fundamentally they boil down to measures protecting the most salient/essential model weights from the first task and preventing training of the second task from overwriting these weights, or at least prevent drastic changes in those parameters. In other words, these mitigations effectively soft partition the DNN into 2 or more smaller virtual DNNs.
The idea that we can functionally split a DNN into smaller logical DNNs may not be very surprising, but it suggests over-provisioning of some DNNs. Indeed, the observation that some DNN architectures can be “trained” to fit even random noise established that their effective capacity is rich enough to essentially memorize the entire dataset [Zhang]. Optimization success is therefore not sufficient to show successful generalization, and the fact that some architectures have the capacity to optimize just about anything, even noise, underlines the risk of overfitting.
Connectionism vs computationalism, probabilism vs determinism. While these ideas appear to be in opposition to each other, in the end they attempt to explain the same world, and finding balance between them often leads to better insight. Neural networks are tools, and it is helpful to be mindful of their weaknesses in order to build more effectively on their strengths. Our goal at Pymedix is to build machine perception technology for medicine, and we see a place for both the connectionist ideas demonstrated in neural networks, but also interpretability of computational approaches.
References
- Zhang, C., Bengio, S., Hardt, M., Recht, B. & Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv:1611.03530 [cs] (2016).