Kris T. Huang, MD, PhD, CTO
Machine learning, and in particular so-called “deep learning,” is an undeniably powerful tool that has revolutionized certain types of classification problems, notably image/object recognition, speech recognition and synthesis, and automated language translation. The lay terms used in association with the field, like “neural,” “intelligence,” “deep,” and “learning,” evoke mental images of something brain-like or mind-like floating around in our computers, akin to an ancestor of HAL 9000. Combine these impressions with classification accuracies that rival or sometimes exceed human performance, and it is understandably convenient to ascribe human-like perceptual abilities to it.
As with any complex system, it was only a matter of time before someone began to probe for vulnerabilities to exploit. Take for example the following images and Google’s Inception v3 image classifier results, along with probability [Athalye 2018]:

Cat, 88%
Guacamole 99%
If I honestly thought the image on the right was guacamole, with even greater conviction than seeing the cat on the left, you’d probably (definitely?) call me crazy and find a new blog to read. And yet this is what Google’s state-of-the-art image classifier said. How about a turtle that gets confused for a gun over 90% of the time?
As with any complex system, it was only a matter of time before someone began to probe for vulnerabilities to exploit. Take for example the following images and Google’s Inception v3 image classifier results, along with probability [Athalye 2018]:

100 photos of a 3D printed turtle from various perspectives and with varying backgrounds. Google TensorFlow’s standard pre-trained Inception v3 classifier identified a rifle in >80% of these samples, some category of gun in >90%, and found a turtle in only 2. Figure from [Athalye 2017].
It’s all fun and games until someone gets hurt. Engineered image manipulations, often imperceptible to humans, termed “adversarial attacks,” can drastically alter the output of a deep learning system at the whim of the attacker. This can have serious implications for safety-critical operations, like in this example:
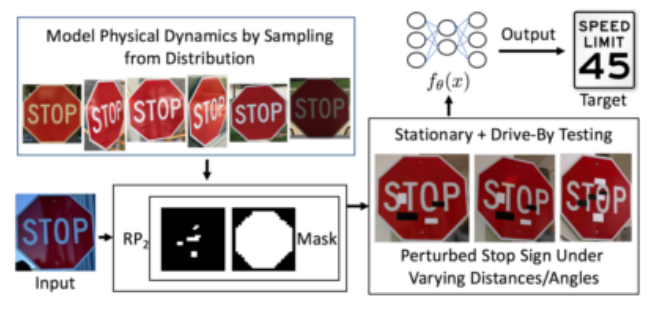
Slight alterations, which would never faze a human, easily tricked a system trained to recognize traffic signs to interpret a stop sign as a speed limit sign. Image from [Eykholt].
Think it can’t happen in medicine? It already has.
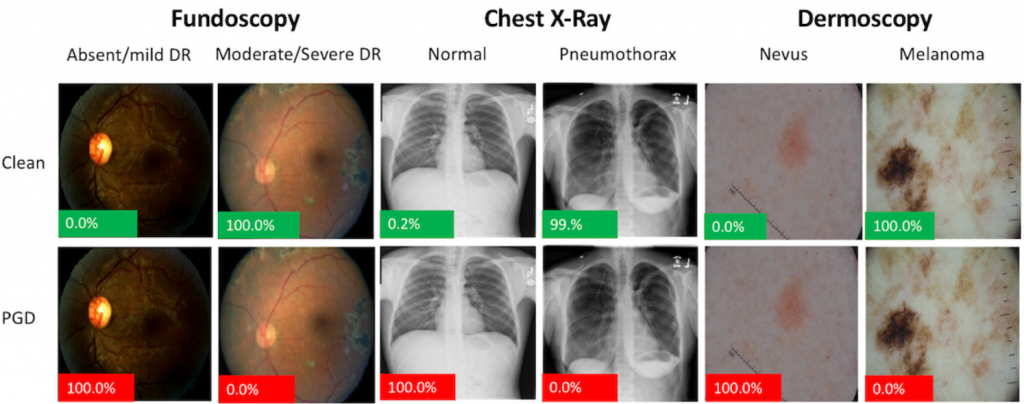
Proof of concept adversarial attacks on medical images. Image shown are pre- (Clean) and post-adversarial attack by Projected Gradient Descent (PGD). The image perturbations are not perceptible to humans. The percentage displayed on the bottom left of each image represents the probability that the model assigns that image of being diseased. Green = Model is correct on that image. Red = Model is incorrect. Image from [Finlayson].
In “Adversarial attacks on medical machine learning” published last week in Science, Finlayson et al. showed that yes, the same sort of human-imperceptible image manipulations can indeed fool medical deep learning systems to falsely detect the presence or absence of a condition practically at will. How this happens is a topic for another day (hopefully soon!), but suffice it to say that Finlayson and his colleagues rightly raise concern over the potential for fraud and patient harm. Mitigations for adversarial attacks have been proposed, but at the expense of accuracy.
A crucial problem with deep learning image classification systems is that, as good as they seem to be at identifying trained subjects, these systems fundamentally do not perceive images in a manner similar to humans. A key observation, presented at ICLR 2019, is that state-of-the-art deep neural networks recognize scrambled images almost as well as the clean image.
…CNNs use the many weak statistical regularities present in natural images for classification and don’t make the jump towards object-level integration of image parts like humans. The same is likely true for other tasks and sensory modalities. [Brendel]
Until those points are addressed, we need to take a step back from machine learning to consider machine perception (recall “Perception as the Prerequisite for Intelligence”). The ability to implement quantitative digital systems with tighter adherence to biological perceptual processes, as we do with Autofuse, will allow us to approach the difficult problems of the day with real confidence, i.e. recognize tabby cats as the furry pets they are instead of confusing them with a chunky, and hopefully fur-free, avocado dip.
References
- Athalye, A., Engstrom, L., Ilyas, A. & Kwok, K. Synthesizing Robust Adversarial Examples. arXiv:1707.07397 [cs] (2017).
- Eykholt, K. et al. Robust Physical-World Attacks on Deep Learning Visual Classification. in Computer Vision and Pattern Recognition (CVPR) (2018).
- Athalye, A., Carlini, N. & Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. in Proceedings of the 35th International Conference on Machine Learning, ICML 2018 (2018).
- Finlayson, S. G. et al. Adversarial attacks on medical machine learning. Science 363, 1287–1289 (2019).
- Brendel, W. Neural Networks seem to follow a puzzlingly simple strategy to classify images. Bethge Lab (2019).
3 thoughts on “Machine Learning Adversarial Attacks: It’s All Fun and Games Until Someone Gets Hurt”
Comments are closed.