Kris T. Huang, MD, PhD, CTO
Make no mistake, neural networks are powerful tools. This class of algorithms single-handedly brought about drastic and rapid advancement in tasks like classification, speech recognition, and natural language processing, bringing about the end of the second “AI winter” that lasted from the late 1980s until around the late 2000s.
Now that neural networks have found their way into our smartphones, cars, and homes, it’s no surprise that they have made inroads in medicine as well. As accomplished as deep learning methods are, in my mind, there are currently some glaring weaknesses that are particularly problematic for safety-critical environments like medicine.
Firstly, while the algorithms’ underlying neural networks are quite well understood, these systems are black boxes in the sense that the resultant models remain difficult to understand, and direct inspection generally does not provide much insight into how it works. They may not actually operate the way we might expect. It is convenient to assume that a machine learning system vaguely patterned after the human brain thinks like a human brain and attacks problems the way humans do, but do they?
A recent presentation at ICLR 2019 by Wieland Brendel and Matthias Bethge of Bethge Lab took a close look at how state-of-the-art deep neural networks solved the classic ImageNet classification task. They found that these systems classify image content based on the features and textures present in the image without regard to their spatial relationships, essentially forming a “bag-of-features” (or bag-of-words) model [Brendel]. If features are the words in an image, the grammar, the relationships between the words, has been completely ignored. This simple but effective strategy was able to surpass human performance on the ImageNet task in 2015 [He], however, as Brendel notes, “if local image features are sufficient to solve the task, there is no incentive to learn the true ‘physics’ of the natural world.” The system isn’t really trying to form an understanding of the scene.

Neural nets are quite good at classifying scrambled images, because they don’t “see” the way humans do.
Relatively recently, weaknesses in deep learning systems have led to a number of adversarial attacks that imperceptibly change the input but reliably and drastically manipulate the system output, namely because neural nets don’t “see” the way humans do. While the earliest examples seemed innocent enough, like confusing a tabby cat for guacamole, later proofs of principle included a turtle mistaken for a gun, and stop signs seen as speed limit signs. There are serious safety implications for any safety-critical field.
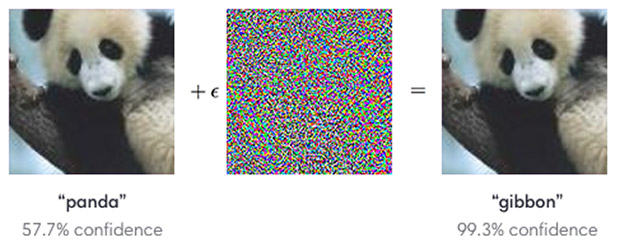
Humans can see that both images depict a panda, but manipulations imperceptible to humans can trick a classifier. Image: OpenAI

The bottom row shows classification results after adversarial manipulation. Misidentification of traffic signs poses safety risks. Image: Papernot et al.
Medicine is no exception. A study from Harvard and MIT confirmed that yes, medical deep learning image classifiers are just as susceptible to attack, and they raise a number of ethical, financial and, of course, safety concerns [Finlayson].
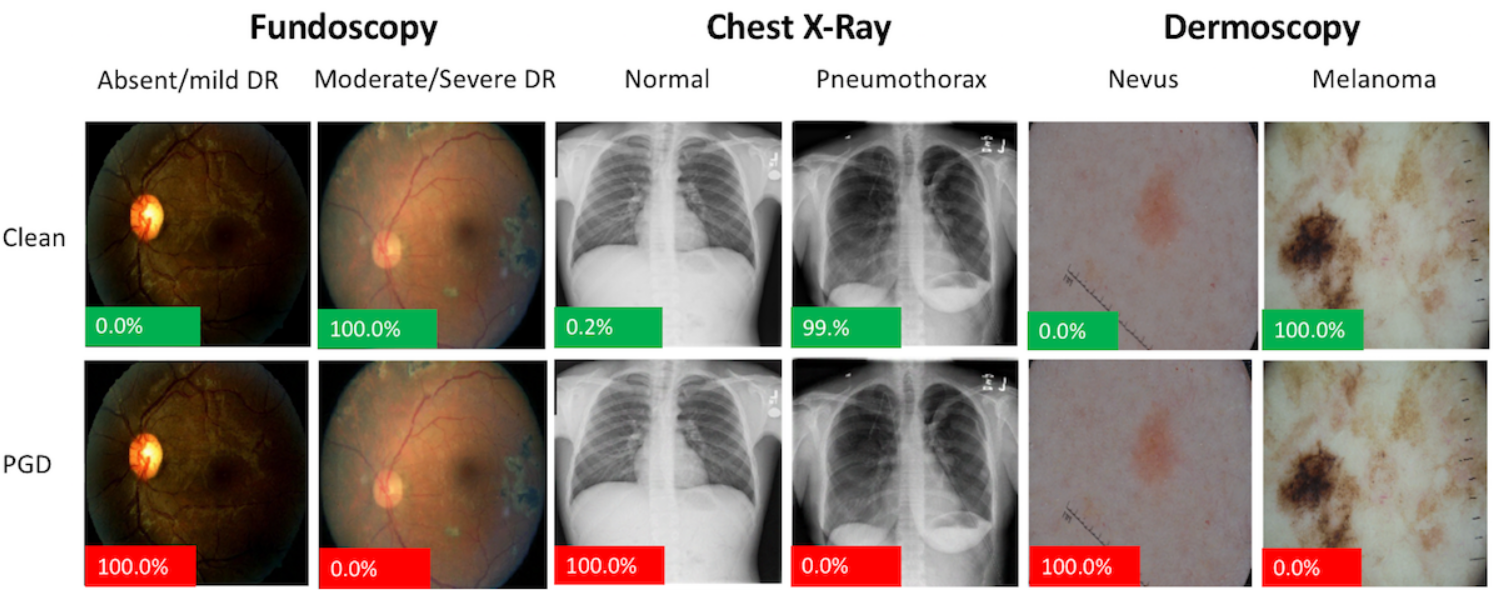
Proof of concept adversarial attacks on medical images. Image shown are pre- (Clean) and post-adversarial attack by Projected Gradient Descent (PGD). The image perturbations are not perceptible to humans. The percentage displayed on the bottom left of each image represents the probability that the model assigns that image of being diseased. Green = Model is correct on that image. Red = Model is incorrect. Image from [Finlayson].
Given the demonstrated susceptibility to human-imperceptible manipulation, deep neural network output is therefore difficult to predict and justify. There are attempts at “explainable” deep learning by adding another, introspective, deep learning system to explain the first. Is this actually better? InterpNET, a neural network designed to generate explanations for another classification network, achieved classification accuracy of about 80% [Barratt]. We’re clearly not there, yet, but would even 95% be good enough? Furthermore, if a neural network can’t explain its output, it can’t tell us whether its model is applicable to the input, either. Unless the training set is also provided with the model, it is difficult to know where the boundaries of clinical applicability are.
This is not to dismiss the usefulness of deep learning. It has clear evidence of success in certain tasks, and we view it as one tool among others in the toolbox. With accessible libraries and numerous platforms to choose from, deep learning may be the shiny object currently getting all the attention, but it isn’t necessarily the right tool for everything. We believe the future will combine the strengths of neural networks and symbolic processing. Human-like robustness, machine-like precision, accuracy and explainability? Look for Autofuse.
References
- Brendel, W. Neural Networks seem to follow a puzzlingly simple strategy to classify images. Bethgelab (2019).
- He, K., Zhang, X., Ren, S. & Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv:1502.01852 [cs] (2015).
- Finlayson, S. G. et al. Adversarial attacks on medical machine learning. Science 363, 1287–1289 (2019).
- Barratt, S. InterpNET: Neural Introspection for Interpretable Deep Learning. arXiv:1710.09511 [cs, stat] (2017).