Kris T. Huang, MD, PhD, CTO
All models are wrong.
But, some are useful.
The idea that “All models are wrong” is generally attributed to statistician George Box [1], but it certainly isn’t new. Of course, even though all models are wrong, it’s clear that some models are quite useful, and good models (should) encapsulate some insight that provides meaning to observed data and an explanation for predictions. A good model should provide insight into a system’s mechanism.
This more traditional scientific notion of the model concept is in fairly stark contrast to today’s growing reliance on so-called “black box” deep learning solutions for increasingly important decision processes. It’s not that deep learning methods are not understood, but the models produced by deep learning typically are, at least for the time being, not interpretable, i.e. they cannot provide explanation for the calculations that led to their predictions.
The need for insight doesn’t just apply to results, it also applies to model formation.
Insight isn’t just interpolation and extrapolation.
Case in point is a historical example, the Hubbert peak theory, which successfully predicted conventional peak oil production in the United States around 1965-1970. Hubbert made this prediction in 1956, at which time this was all the data he had:
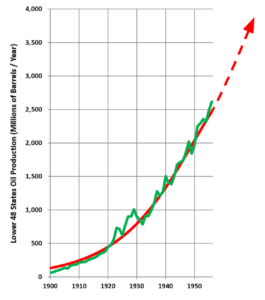
(Green) The oil production data available to Hubbert at the time he predicted Peak Oil.
(Red) Just about any reasonable trend line.
Image credit: Wikipedia, with edits by Pymedix
While most any reasonable trend line, and likely any reasonable machine learning algorithm, will happily extrapolate oil production to a nonsensical infinity, Hubbert had a few key, if not now obvious, insights to guide his prediction:
- Production at first increases approximately exponentially, as more extraction commences and more efficient facilities are installed, and
- As the resource is depleted, it becomes harder to extract, and production begins declining until it approximates an exponential decline.
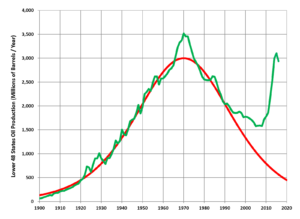
Hubbert’s upper-bound prediction for US crude oil production (1956), and actual lower-48 states production through 2016. The increase beginning in the 1990’s and exploding in the 2000’s was a result of large-scale hydraulic fracturing (fracking) and its subsequent boom.
Image credit: Wikipedia
Sure, any machine learning method will fit the more complete data after the fact, but by then we’ve already missed the boat, and it still wouldn’t provide any useful explanations, interpretations, or even hypotheses as to what’s going on. Now, Hubbert wasn’t quite right (ie, wrong) on some of his assumptions, yet nonetheless it has served as a useful model over the decades since, for a variety of natural resources. Is it wrong? Yes. But is it useful (and explanatory)? Also yes.
Machine learning may be great at interpolating, but extrapolating remains a hobby.
Image credit: XKCD
While much work is being done to try to explain deep learning (using yet another deep learning system), even more effort has been put toward improving prediction accuracy, typically by increasing the size of the model along with computational requirements. For example, Google’s Tacotron 2 speech synthesizer uses about 13M parameters (up from 4M from its predecessor). Open AI’s latest GPT-3 language model has 175B parameters (up from 1.5B from 2019’s GPT-2). For all that, as impressive as GPT-3 is, it still falls flat on many simple queries. It is trained to predict text, given some text. It is not trained to “understand.” It doesn’t detect nonsense, and it doesn’t know how to say “I don’t know.” Is GPT-3’s model wrong? Yes. Is it useful? Maybe as a fun diversion, but I wouldn’t trust it in safety-critical situations.

Image credit: XKCD
The steady diffusion of deep learning models into everyday life, coupled with their lack of transparency, have led to concerns over their use in high stakes decisions [2], including healthcare.
We believe that AI can be accurate, precise, and interpretable all at the same time. Deep learning has been an incredible tool over the past decade and will continue to be important in the future. However, it is pretty clear that sheer data and brute force computing power, on their own, won’t produce satisfactory models, from the perspective of the scientific method. Even the authors of GPT-3 acknowledge this [3]:
“A more fundamental limitation of the general approach described in this paper – scaling up any LM-like model, whether autoregressive or bidirectional – is that it may eventually run into (or could already be running into) the limits of the pretraining objective.”
and,
“…scaling pure self-supervised prediction is likely to hit limits, and augmentation with a different approach is likely to be necessary.”
Insight isn’t only the goal, it seems to be a prerequisite. Biologically, the initial “insight” may be provided by the evolution-derived structure of the brain itself, which is pretty strongly conserved between people and even species.
The technology in Autofuse is founded upon a few key insights:
- Human vision is the gold standard in medical image registration.
- The human visual system is largely composed of well-understood, fixed-function parts that do not require any training.
- Human anatomy is variable, but still subject to physically plausible deformations.
It is no surprise then that Autofuse exhibits:
- A human-like ability to perform deformable registration of 3D medical images automatically, without training, no initial rigid registration or other input needed.
- Interpretable decisions and actions, because it follows well-established rules and logic.
References
- Box, G. E. P. (1976), “Science and statistics”, Journal of the American Statistical Association, 71 (356): 791–799, doi:10.1080/01621459.1976.10480949
- Rudin C, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead”, Nature Machine Intelligence, Vol 1, May 2019, 206-215. doi:10.1038/s42256-019-0048-x
- Brown TB, et al, “Language Models are Few-Shot Learners”, arXiv:2005.14165.